요즘 내 포트폴리오를 정리해두려고 많은 노력중에 있다.
(널널한 방학 때 미리 해놓으면 좋겠지라는 생각으로...ㅋ)
포트폴리오는 깃허브, 링크드인, 티스토리 이렇게 세개를 메인으로 두고 가려고 한다.
그래서 이전에 했던 프로젝트에 대한 paper, ppt, code들을 싹싹 찾아내고 있다.
오늘은 그 중 학부시절 4학년 때 했던 프로젝트 중 한개를 가져왔다.

코드
사용했던 코드와 paper, ppt자료들은 밑 링크에서 확인해볼 수 있다.
https://github.com/yejining99/NewCF
GitHub - yejining99/NewCF: A New Collaborative Filtering at Recommendation System Using Yahoo! Music Data
A New Collaborative Filtering at Recommendation System Using Yahoo! Music Data - GitHub - yejining99/NewCF: A New Collaborative Filtering at Recommendation System Using Yahoo! Music Data
github.com
A New Collaborative Filtering at Recommendation System Using Yahoo! Music Data
우리 학부는 졸업 전에 프로젝트 랩 이라는 수업을 필수로 들었어야했는데, 그때 주제로 잡은 프로젝트이다.
그때 한참 추천시스템이라는 분야에 관심을 가지기 시작했던 때라, 더 효율적인 추천시스템이라는 주제를 선정하게 되었다.
특히 Yahoo! Music Data는 추천시스템의 기본 중에 기본 데이터셋인 만큼 한 번쯤 다뤄보고 싶다는 생각도 있었다.
이 프로젝트는 야후에서 제공되는 음악 데이터에 대한 추천 시스템을 더 효율적으로 만들기 위해 수행되었다.
특히 새로운 사용자가 들어올 때 알고리즘이 실행되는 데 걸리는 시간을 줄이는 데 초점을 맞췄다.
또한 사용자와 음악의 Interaction만 사용하던 기존 SVD 알고리즘과는 달리 앨범, 노래 가수 등의 정보를 반영하는 방법을 생각해 보았다.
NewCF : 새로운 알고리즘

위 그림이 우리가 생각해낸 알고리즘의 framework이다.
각각의 순서는 다음과 같다.
- 1단계: Yahoo! Music User Ratings data를 준비한 후 각각을 합쳐준다.
- 2단계: 'Unknown' 장르에 대한 앨범을 clustering하기 위해 다른 장르들의 코사인 유사성 가져온다.
- 3단계: HDBSCAN을 강화하기 위해 사전 처리로 UMAP를 사용한다.
- 4단계: HDBSCAN을 사용하여 'Unknown' 장르를 클러스터링합니다.
- 5단계: user upper bound formula을 사용하여 사용자를 각 장르 범주로 분류한다.
- 6단계: 장르별로 SVD 알고리즘을 실행하여 rating을 예측한다.
- 7단계: 예측된 점수를 내림차순을 나열한다.
- 8단계: 추천할 노래를 선택한다.
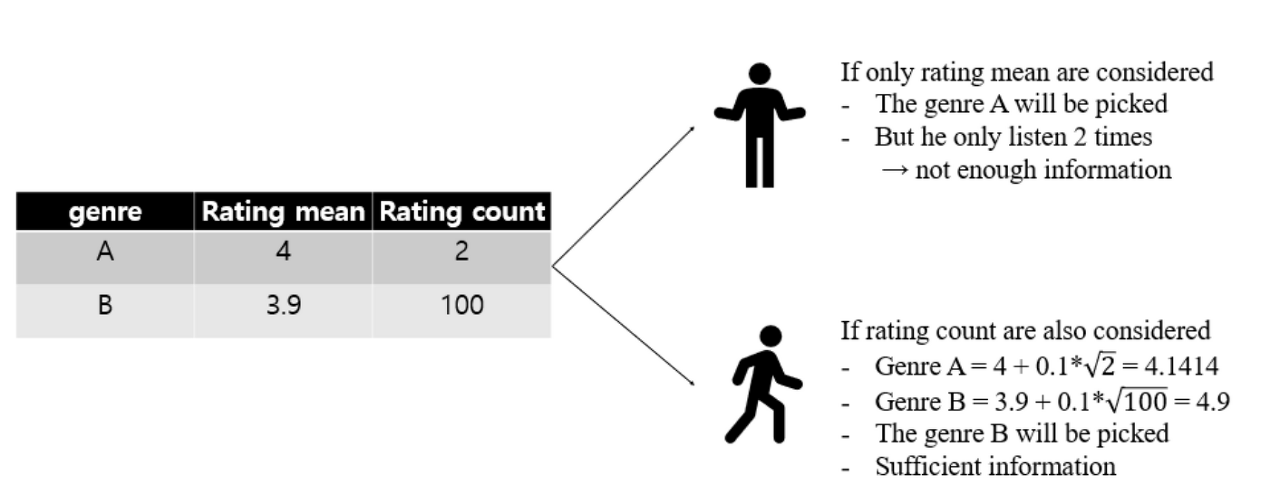
Upper Bound Formula란?
Upper Bound Formula를 사용하는 이유는 rating 수를 고려하여 사용자에게 더 적합한 장르 범주를 제공할 수 있기 때문이다.
다음과 같은 예들을 생각해 보면 더 이해가 될 것인데, 예를 들어 한 사용자가 a와 b 장르에 대해 4와 3.9의 평점을 줬다고 가정해보자.
사실, 4와 3.9 사이에는 큰 차이가 없다.
하지만 점수만이 장르를 선택하는 유일한 이유이다.
실제로 사용자는 A 장르의 노래 두 곡만 들었다.
따라서 장르 b가 사용자에게 더 적합해 보인다.
따라서 이 문제를 방지하기 위해 사용자가 더 많이 들은 장르에 가중치를 부여하기 위해 상한 공식을 사용했다.
결과
우리가 목표로 잡은 새로운 사용자가 들어올 때 알고리즘이 실행되는 데 걸리는 시간을 줄이는 것에 대한 결과를 알아보기 위해, 우리는 원래 SVD 알고리즘과 우리가 만든 알고리즘 사이의 실행 시간을 비교해보았다.
파이썬 내의 시간 모듈을 사용하여 알고리즘을 실행하는 데 걸리는 시간을 계산할 수 있었다.
결과는 다음과 같다.

기존의 SVD는 590초가 걸린 반면에 우리의 알고리즘은 60초밖에 걸리지 않은 것을 확인할 수 있었다.
또한 새로운 user가 들어오면 처음부터 다시 돌려야하는 SVD와 달리, 우리의 알고리즘은 유저를 clustering하고, 더 적은 수의 데이터로 SVD를 돌리면 되므로 시간이 훨씬 줄어들 것이다.
느낀점
엄청 복잡한 알고리즘 개선을 한 것은 아니지만, 음악시장을 이해하고 그에 맞는 특성을 반영하는 것에 의의가 있는 프로젝트였다.
또한 추천시스템의 고질적인 문제인 cold start, time complexity또한 어떻게 개선시킬 수 있을까 생각해볼 수 있었다.
그리고 알고리즘을 이해하고 이를 코드로 풀어나가는 과정에서 많은 것을 배울 수 있었던 것 같다.
'Data Science > Portfolio' 카테고리의 다른 글
| [Kaggle] Change Point Detection | 시계열 변화하는 포인트 탐지 (4) | 2023.01.10 |
|---|---|
| 포트폴리오 정리 사이트 추천 (3) | 2023.01.06 |
| [Project] 기숙사 택배실 문제 해결📦/정수계획법/선형계획법/최적화 (0) | 2022.03.25 |
| [대회] 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회-3/time series/시계열데이터/전처리/모델 (0) | 2022.03.04 |
| [대회] 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회-2/셰일가스생산/시계열데이터 (0) | 2022.02.27 |



