안녕하세요,
데이터 사이언티스트를 꿈꾸는 yejining입니다. 🍓👩💻
오늘은 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회에서 사용했던 시계열 데이터 전처리 방식과 어떤 모델을 사용했는지 적어볼까 합니다.
아마 이번 포스팅이 대회 관련 마지막 포스팅이 될 듯 하네요!
그럼 고고링~

1. multivariate + multiple time series
우선 multivariate time series 와 multiple time series가 뭔지 모르시는 분은 이전 포스팅을 참고해주세요 😎
2022.02.27 - [Data Science/Portfolio] - [대회] 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회-2/셰일가스생산/시계열데이터
[대회] 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회-2/셰일가스생산/시계열데이터
안녕하세요, 데이터 사이언티스트를 꿈꾸는 yejining입니다. 🍓👩💻 오늘은 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회에서 사용했던 셰일가스 데이터를 소개하고 특히 시계열 데이터
yejining.tistory.com
간단히 적어보면 multivariate time series는 변수가 다양한 시계열 데이터를,
multiple time series는 다양한 곳에서 얻은 시계열을 말합니다.
그림으로 나타내보자면 이런식이라고 할 수 있겠죠!

그런데 대회에서 주어진 데이터는 multivatiate + multiple time series였답니다!!

이런식으로 변수가 3개가 있는 생산정들이 n개 있었던 것이죠.
변수 1은 셰일가스 생산량,
변수 2는 다른 가스들 생산량,
변수 3은 조업시간에 대한 데이터였습니다.
문제에서 해결해야하는 것은 "어떤 모르는 생산정의 이전 시계열 데이터가 주어졌을 때, 변수 1 즉 셰일가스의 이후 6개월 생산량 평균을 예측하는 것" 이었답니다.
아.. 만약에 multivatiate, multiple time series가 아니면 그냥 시계열 모델을 사용하면 되는데,
이건 어떤식으로 해야할까요..?🥲
2. 시계열 데이터 전처리
이러한 데이터에서는 전처리가 매우 중요합니다.
저희는 전처리를 위해 3가지 fundamental features를 사용했습니다.
1. lag

첫번째 lag는 얼마만큼의 과거 데이터를 사용할 것인지를 나타내는 값입니다.
시계열 데이터는 이전 데이터가 지금 데이터에 영향을 주기 때문에, 이러한 lag를 두어 이전데이터를 분석에 적용하려고 하는 것 입니다.
예를 들어 lag를 2이라고 두었다면, time이 3인 데이터는 time이 1,2인 데이터를 또다른 변수로 가지게 되는 것입니다.
2. difference

두번째 difference는 과거 데이터와의 차이를 나타내는 값입니다.
현재 데이터 빼기 과거데이터를 하면 difference가 되는데요.
이거는 시계열 데이터를 다뤄보신 분들이라면 한번쯤 접해보셨을 듯 합니다.
예를 들어 difference를 2로 잡았다면 time 3인 데이터는 time 3의 값 빼기 2의 값, 그리고 time 3의 값 빼기 1값이 됩니다.
3. step

마지막 step은 얼마만큼의 미래를 예측할 것인가입니다.
저희는 6개월의 셰일가스 생산량을 예측해야 했으므로, step을 6으로 주면 되겠죠.
++추가
time이 앞쪽인 데이터들은 lag와 difference를 줄 수 없겠죠.
왜냐하면 이전 데이터가 없으닌깐요!
그런 데이터는 삭제해줬습니다.
그리고 저희가 예측해야하는 생산정, 즉 test데이터에 있어서도 이전 시계열 데이터들이 존재합니다.
그 데이터들도 모델을 train할 때 사용해주었습니다.
4. 결과

step은 저희가 해결해야하는 문제 상 6으로 두었고, lag와 difference는 값을 줘야하는 hyperparameter가 됩니다.
그래서 결과적으로 lag와 difference에 다양한 값을 줘본 결과 5가 가장 좋은 정확도를 보였답니다!
그러면 대충 데이터가 이런 형태를 가지게 됩니다.
3. 모델 설명
위에 전체적인 데이터 모양을 보면, 시계열 데이터가 table형태로 변환된 것을 확인하실 수 있습니다!
그래서 이 데이터는 특별한 시계열 모델이 아닌 그냥 머신러닝 모델에도 적용할 수 있게 됩니다.
저희는 stacking ensemble기법을 사용해서 모델을 구성하였습니다.

stacking ensemble기법이란 데이터를 여러 예측모델에 넣은 후 각 모델의 예측값을 또다른 모델의 input값으로 사용하는 방법인데요.
이 방법은 단일 모델을 사용하는 것 보다 훨씬 정확하다는 장점이 있습니다.
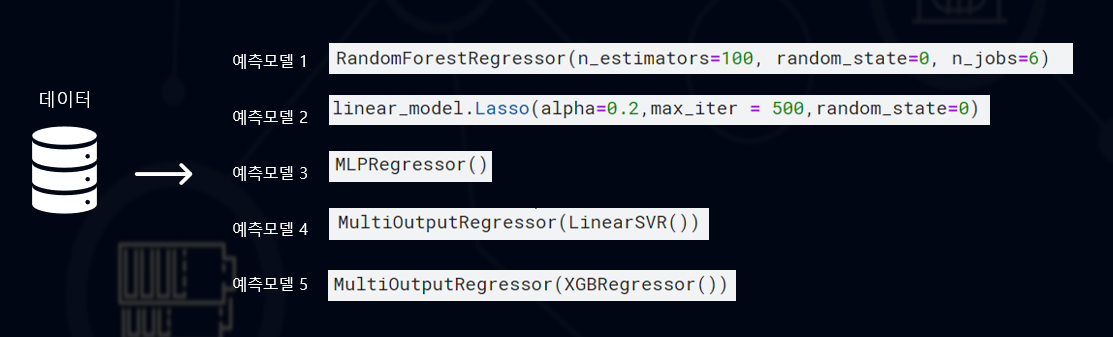
그래서 우선 아까 table형태로 변환되었던 데이터들을 총 5가지 모델에 넣었습니다.
각 모델은 randomforest regressor, Lasso, Multi-layer Perceptron regressor, Linear Support Vector Regression, Extreme Gradient Boosting입니다.
모델을 선택할 때 과적합을 피할 수 있도록 선형적 모델이라던지 미리 모델 성장을 멈추는 앙상블기법을 이용하는 모델을 주로 선택하였습니다.
물론 각각의 모델은 최고의 성능을 낼 수 있도록 hyperparameter 작업을 거쳐주었구요.
각 모델은 6개월 생산량을 따로따로 예측해야하기 때문에 MultiOutputRegressor 방법을 적용해주었습니다.

그럼 총 5가지 예측모델에서 각각 6가지 output이 나올텐데요,
이것을 평균내어 x데이터로 사용하였습니다.
그리고 예측해야하는 y값에는 실제 셰일가스의 6개월 평균 값을 넣어주었구요.
최종 모델은 이전 5개의 모델 중에서 가장 정확도가 높았던 random forest를 사용했습니다.
이 방법을 통해 6개월을 각각 예측하고 이를 6개월 평균값으로 변환할 수 있었습니다.

그 결과...
최종적으로 예측 정확도가 3번째로 높았답니다!
4. 코드공유
마지막으로 사용했던 코드를 공유합니다 😊
무단배포는 금지합니다 ❎
# 사용했던 library
import numpy as np
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from scipy.optimize import curve_fit
import random
import warnings
from sklearn.ensemble import RandomForestRegressor
from sklearn import linear_model
from sklearn.neural_network import MLPRegressor
from sklearn.svm import LinearSVR
from xgboost import XGBRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import LinearRegression
from sklearn.multioutput import MultiOutputRegressor
from sklearn.preprocessing import StandardScaler, MinMaxScaler, RobustScaler, PowerTransformer, PolynomialFeatures
from sklearn.pipeline import Pipeline
# 데이터 불러오기
df = pd.read_csv('trainSet.csv')
exam_df = pd.read_csv('examSet.csv')
# lag와 step사이즈는 변경시킬 class 만들기
class multiple_time_series:
def __init__(self,df,exam_df,window,step):
self.df = df
self.exam_df = exam_df
self.window = window
self.step = step
def one_step_target(self):
melt = self.df
step = self.step
for i in range(1,step+1):
melt['q_next_week'+str(i)] = melt.groupby("No")['q'].shift(-1*i)
return melt
def exam_one_step_target(self):
melt = self.exam_df
step = self.step
for i in range(1,step+1):
melt['q_next_week'+str(i)] = melt.groupby("No")['q'].shift(-1*i)
return melt
def lag_and_diff(self):
num = self.window
melt_train = self.one_step_target()
for i in range(1,num+1):
melt_train["q_lag"+str(i)] = melt_train.groupby("No")['q'].shift(i)
melt_train["q_diff"+str(i)] = melt_train.groupby("No")['q'].diff(i)
melt_train["other_lag"+str(i)] = melt_train.groupby("No")['other'].shift(i)
melt_train["other_diff"+str(i)] = melt_train.groupby("No")['other'].diff(i)
melt_train["hour_lag"+str(i)] = melt_train.groupby("No")['hour'].shift(i)
melt_train["hour_diff"+str(i)] = melt_train.groupby("No")['hour'].diff(i)
return melt_train
def exam_lag_and_diff(self):
num = self.window
melt_train = self.exam_one_step_target()
for i in range(1,num+1):
melt_train["q_lag"+str(i)] = melt_train.groupby("No")['q'].shift(i)
melt_train["q_diff"+str(i)] = melt_train.groupby("No")['q'].diff(i)
melt_train["other_lag"+str(i)] = melt_train.groupby("No")['other'].shift(i)
melt_train["other_diff"+str(i)] = melt_train.groupby("No")['other'].diff(i)
melt_train["hour_lag"+str(i)] = melt_train.groupby("No")['hour'].shift(i)
melt_train["hour_diff"+str(i)] = melt_train.groupby("No")['hour'].diff(i)
return melt_train
def split(self):
num=self.window
melt = self.lag_and_diff()
melt = melt.dropna()
point = 30
melt_train = melt[melt['MONTH'] < point].copy()
melt_valid = melt[melt['MONTH'] >= point].copy()
return melt_train, melt_valid
def exam_split(self):
num=self.window
exam_melt = self.exam_lag_and_diff()
exam_melt = exam_melt[exam_melt['MONTH']>num]
point = 24
exam_melt_train = exam_melt[exam_melt['MONTH'] < point].copy()
exam_melt_valid = exam_melt[exam_melt['MONTH'] >= point].copy()
return exam_melt_train, exam_melt_valid
def SMAPE(self, true, pred):
return np.mean((np.abs(true-pred))/(np.abs(true) + np.abs(pred)))*100
def train_data(self):
melt_train, melt_valid = self.split()
exam_melt_train, exam_melt_valid = self.exam_split()
step = self.step
window = self.window
melt_train = pd.concat([melt_train,exam_melt_train])
Xtr = melt_train.drop(['No','MONTH'],axis=1)
lis = []
for i in range(1,step+1):
qq = 'q_next_week'+str(i)
lis.append(qq)
Xtr = Xtr.drop([qq],axis=1)
Ytr = melt_train[lis]
return Xtr,Ytr
def RandomForest(self):
Xtr,Ytr = self.train_data()
model1 = RandomForestRegressor(n_estimators=100, random_state=0, n_jobs=6)
model1.fit(Xtr,Ytr)
return model1
def Lasso(self):
Xtr,Ytr = self.train_data()
model2 = linear_model.Lasso(alpha=0.2,max_iter = 500,random_state=0)
model2.fit(Xtr,Ytr)
return model2
def MLP(self):
Xtr,Ytr = self.train_data()
model3 = MLPRegressor()
model3.fit(Xtr,Ytr)
return model3
def SVR(self):
Xtr,Ytr = self.train_data()
model4 = MultiOutputRegressor(LinearSVR())
model4.fit(Xtr,Ytr)
return model4
def xgboost(self):
Xtr,Ytr = self.train_data()
model = MultiOutputRegressor(XGBRegressor())
model.fit(Xtr,Ytr)
return model
def evaluate(self,model,a = 'aa'):
melt_train, melt_valid = self.split()
exam_melt_train, exam_melt_valid = self.exam_split()
step = self.step
e_melt_valid = exam_melt_valid[exam_melt_valid['MONTH']<(30-step)]
melt_valid = pd.concat([melt_valid,e_melt_valid])
Xval = melt_valid.drop(['No','MONTH'],axis=1)
lis = []
for i in range(1,step+1):
qq = 'q_next_week'+str(i)
lis.append(qq)
Xval = Xval.drop([qq],axis=1)
Yval = melt_valid[lis]
if a == 'stack':
model.estimator.final_estimator_ = model.estimator.final_estimator
model.estimator.estimators_ = model.estimator.estimators
model.estimator.stack_method_ = model.estimator.stack_method
pp = model.estimator.predict(Xval)
else:
pp = model.predict(Xval)
smape = self.SMAPE(Yval,pp)
return smape
def stacking(self,model1,model2,model3,model4,model5):
melt_train, melt_valid = self.split()
exam_melt_train, exam_melt_valid = self.exam_split()
step = self.step
e_melt_valid = exam_melt_valid[exam_melt_valid['MONTH']<(30-step)]
melt_valid = pd.concat([melt_valid,e_melt_valid])
Xval = melt_valid.drop(['No','MONTH'],axis=1)
lis = []
for i in range(1,step+1):
qq = 'q_next_week'+str(i)
lis.append(qq)
Xval = Xval.drop([qq],axis=1)
Yval = melt_valid[lis].mean(axis=1)
p1 = model1.predict(Xval).mean(axis=1)
p2 = model2.predict(Xval).mean(axis=1)
p3 = model3.predict(Xval).mean(axis=1)
p4 = model4.predict(Xval).mean(axis=1)
p5 = model5.predict(Xval).mean(axis=1)
df = pd.DataFrame({'p1':p1,
'p2':p2,
'p3':p3,
'p4':p4,
'p5':p5,
'real':Yval})
return df
def regression(self,model1,model2,model3,model4,model5):
df = self.stacking(model1,model2,model3,model4,model5)
x = df[['p1','p2','p3','p4','p5']]
y = df[['real']]
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.9, test_size=0.1)
mlr=RandomForestRegressor(n_estimators=100, random_state=0, n_jobs=6)
mlr.fit(x_train,y_train)
#pp = mlr.predict(x_test)
#smape = self.SMAPE(y_test,pp)
return mlr
def final(self,model1,model2,model3,model4,model5,model6):
exam_melt_train, exam_melt_valid = self.exam_split()
step = self.step
exam_melt_valid = exam_melt_valid[exam_melt_valid['MONTH']==30]
Xval = exam_melt_valid.drop(['No','MONTH'],axis=1)
lis = []
for i in range(1,step+1):
qq = 'q_next_week'+str(i)
lis.append(qq)
Xval = Xval.drop([qq],axis=1)
p1 = model1.predict(Xval).mean(axis=1)
p2 = model2.predict(Xval).mean(axis=1)
p3 = model3.predict(Xval).mean(axis=1)
p4 = model4.predict(Xval).mean(axis=1)
p5 = model5.predict(Xval).mean(axis=1)
df = pd.DataFrame({'p1':p1,
'p2':p2,
'p3':p3,
'p4':p4,
'p5':p5})
pp = model6.predict(df)
no = exam_melt_valid['No'].to_numpy()
fin = pd.DataFrame({'No':no,
'predict':pp.flatten()})
return fin
# 첫번째 모델 돌리기
print('window size가 5일때')
print('randomforest: ',sample.evaluate(RandomForest).mean())
print('Lasso: ',sample.evaluate(Lasso).mean())
print('MLP: ',sample.evaluate(M).mean())
print('SVR: ',sample.evaluate(SVR).mean())
print('xgboost: ',sample.evaluate(xgboost).mean())
#마지막 모델 돌리기
regress = sample.regression(RandomForest,Lasso,M,SVR,xgboost)
sample2 = multiple_time_series(df,exam_df,5,6)
sample2.final(RandomForest,Lasso,M,SVR,xgboost,regress)
'Data Science > Portfolio' 카테고리의 다른 글
| [Project] A New Collaborative Filtering at Recommendation System Using Yahoo! Music Data (2) | 2023.01.06 |
|---|---|
| [Project] 기숙사 택배실 문제 해결📦/정수계획법/선형계획법/최적화 (0) | 2022.03.25 |
| [대회] 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회-2/셰일가스생산/시계열데이터 (0) | 2022.02.27 |
| [대회] 제1회 UNIST-POSTECH-KAIST 데이터사이언스 경진대회-1/참가후기 (0) | 2022.02.24 |
| [Project] 다중선형회귀(multiple linear regression)를 통해 귤 썩는 날 예측하기/파이썬 구현/시각화/예제 (2) | 2022.02.22 |



